| Tweet |
In my project, we have a table that tells us the last refresh time of the replication database. We compare it with current time to find out the lag in mins.
For the purpose this blog, I have created a table called dim that serves the same purpose. This table has 1 row and 1 column. The possible values in this column are
1. First
2. Second
When the value in dim table is 'First' we will want the first database (replication database) to be queried and when the value is 'Second' we will want the second database (primary database) to be queried.
Let us now look at the implementation.
Let us start with the physical layer.

I have 2 database objects in my physical layer.
Note: 'Vishal' database object here is my replication database. 'Vishal switching db' is my primary database.
Vishal database object has a view called First_DB. This view has the following query.
select 'First_DB' as First_db_col from dual
Similarly Second_DB of Vishal switching db database object has the following definition.
select 'Second_DB' as Second_db_col from dual
I have already given the description of dim table in the beginning of this blog.
Let us now look at the joins between these tables.

The join between Second_Db and dim is 1=1.
This join has been put in place because we need dim table for fragmentation. Hence a join in the physical layer will be necessary. However, we don't have a key or any logical relation to join the tables. So the join is 1=1 as shown below.

Similarly the join between First_DB and dim is also 1=1.
The difference between Second_DB-dim join and First_DB-dim join is that Second_DB-dim join is a cross database join while First_DB-dim join is not.
Let us now look at the BMM layer

We have dragged both the views i.e. First_DB and Second_DB into a logical fact called Switching table.
We have created a dimension out of the dim table.
Switching column is a logical column and is mapped to both First_DB and Second_DB.

The logical table source (LTS) First DB has the following fragmentation content and level setting.

Note that the 'This source should be combined with other sources at this level' check box is checked.
Similar setting exists for the LTS Second DB. The Fragmentation content of Second DB LTS is
"Vishal"."dim"."dim_column" = 'Second'
Dim hierarchy is a regular level based hierarchy created on top of the dim table.
The join in the BMM layer look like the following.

The join in the BMM layer look like the following.

This whole model is dragged into the presentation layer.
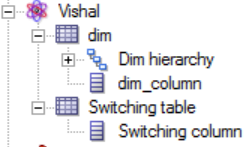
Let us now look at the Analysis part and the physical SQL created by the analysis.
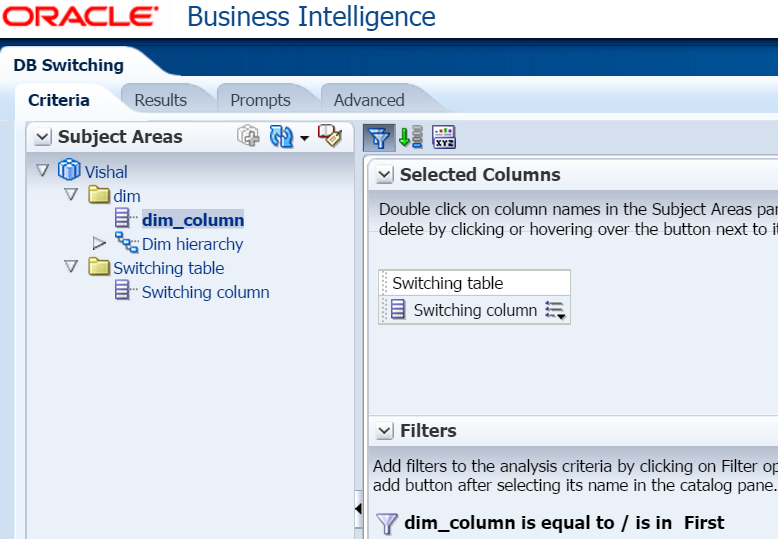
Note that I have hardcoded First in the filter. In a project, you would want to use a variable here. This variable can be linked to an init block or can be a presentation variable. This init block should find out the lag in the replication server and then put either First or Second as a value in the variable.
The result is

Similarly, if your variable gets the value of Second then your result will be


Let us now look at the physical SQL generated by the 2 queries.
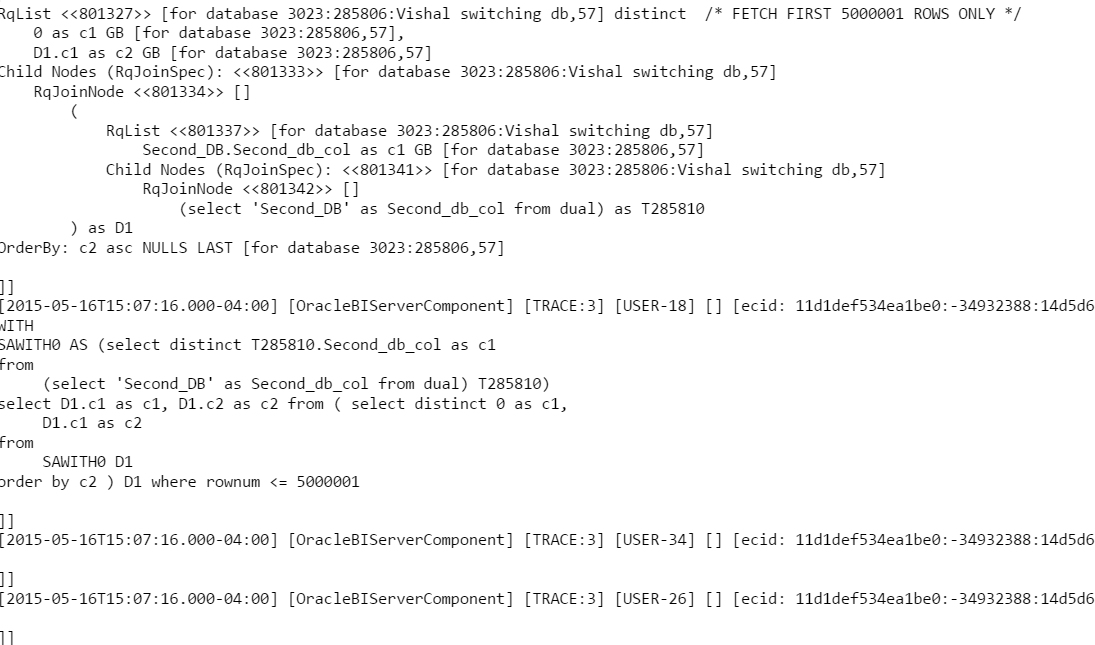
Query when First is put as the filter is
WITH
SAWITH0 AS (select distinct T285804.First_db_col as c1
from
(select 'First_DB' as First_db_col from dual) T285804)
select D1.c1 as c1, D1.c2 as c2 from ( select distinct 0 as c1,
D1.c1 as c2
from
SAWITH0 D1
order by c2 ) D1 where rownum <= 5000001
------------------------------------------------------------------------------
Query when Second is put as the filter is
WITH SAWITH0 AS (select distinct T285810.Second_db_col as c1 from (select 'Second_DB' as Second_db_col from dual) T285810) select D1.c1 as c1, D1.c2 as c2 from ( select distinct 0 as c1, D1.c1 as c2 from SAWITH0 D1 order by c2 ) D1 where rownum <= 5000001We note that OBIEE only sends the query to the relevant database. Screenshots of the queries are shared below.

Note the following1. The log does not even have the query fired on the dim table. This is because the joins are such that the dim table is not required to fulfill this request.2. The correct LTS is picked up based on the value passed as a filter from the analysis.3. dim table will be required in the init block that will load the variable used as a filter in the analysis.Till next time ..
2 comments:
Hi Vishal, went through this post. Can you please tell me the significance of the below:
1) Why cross DB join?
2) Why only one value in table at a time for Fragmentation Content?
Thx
1. Because you only have to maintain the table used for switching (dim) in this case, in one of the 2 databases.
2. Because you have to switch the database.
I dont think you understood the blog at all.
Post a Comment