This is another one of those articles where I pick a topic from the sample chapter of my book and share with you. Some of the other discussions in this blog from the sample chapter of my book are on dynamic breadcrumbs, data densification and ReForms. In this post, we will see 3 different ways of creating a Matrix report a.k.a Crosstab report a.k.a Pivoted report.
Let me first explain the concept of a matrix report. Matrix reports are helpful when want to slice and dice a measure on two or more dimensions. For example, let's say, we want to know the count of people for every combination of shirt color and pant color. A matrix report for this will look like the following:

Let us now look at the various ways of creating a matrix report in APEX.
We will talk about the following 3 ways of creating Matrix reports.
1. Creating Matrix reports using substitution variable
2. Creating Matrix reports using dynamic PL/SQL region of APEX
3. Creating Matrix reports using Pivot XML operator
I have created a sample application that presents all these 3 methods of implementing Matrix reports. Find the link below:
https://apex.oracle.com/pls/apex/f?p=81782:5:0:::::
Let me also share a screenshot of the Matrix report.

Let us now see the process to create matrix report using substitution variables
Creating Matrix reports using substitution variable
Oracle 11g has a feature called Pivot operator. Pivot operator can help us achieve our objective. The only problem with this operator is that it has a static IN clause. Pivot XML can however use sub queries.
Let me first talk a little about the Pivot operator.
The basic function of a query using the Pivot operator is to aggregate the data based on the function written in its list clause and transpose the rows of the aggregated result as columns. The pivot operator has three clauses namely, the list clause, the for clause, and the in clause. The list clause describes the aggregation functions such as sum and avg. The for clause lists the columns which are to be grouped and pivoted. The in clause lists the columns which will appear in the output.
Now the problem is that the in clause can only have a static list of values. The developer obviously, does not know the number of columns that will appear in the final result. The solution is to pass a page item as a substitution variable in the in clause. This page item can be fed with the right list of values on the fly and hence the arrangement give the same results as a dynamic in clause would.
We will use the same item(P5_DEPT_LIST) in the in clause of the PIVOT operator and also in framing the column headings. Hence the data and the headings would always be in sync. Let me now share the query of the region source to make more sense of the discussion.
with pivot_data as (
SELECT department_id, job_id, salary
FROM oehr_employees
)
SELECT *
FROM pivot_data
PIVOT (
SUM(salary)
FOR department_id
IN (&P5_DEPT_LIST.) -- Substitution variable in the in clause
)
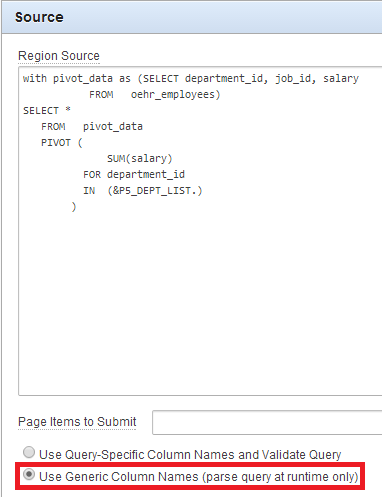
Note that the number of columns in the result will depend on the number of values, stored as a list, in P5_DEPT_LIST page item. Hence the number of columns and their names will not be known at the time of coding. So, it is important that we check the Use Generic Column Names check box as shown below.
select listagg(department_id,',') WITHIN GROUP (ORDER BY department_id) from (select distinct department_id from oehr_employees)
The output of this code is: 10,20,30,40,50,60,70,80,90,100,110
listagg function, in the above code, aggregates strings. It lets us order our data using the order by clause and also allows us to supply a separator for the values in the list. Many more methods of string aggregation are discussed in the book.
P5_DEPT_LIST is then passed as an argument to the in clause, as shown in the query shared above.
We use the same item i.e. P5_DEPT_LIST to form the column headings of the columns. Have a look at the screenshot below:

Check https://apex.oracle.com/pls/apex/f?p=81782:5:0::::: to see the implementation that uses PIVOT query with substitution string for generating Matrix report.
Creating Matrix reports using dynamic query region
We can also create Matrix reports using APEX's dynamic query region. Let us talk about it now.
APEX has a feature that allows us to write a query string as the source of a region and APEX displays the data after running the query string. This type of region is called 'SQL Query (PL/SQL function body returning SQL Query)'. We can concat the query with P5_DEPT_LIST and get our Matrix report. This method does not use substitution strings.
I am pasting the region source for your convenience.
begin
return 'with pivot_data as (
SELECT department_id, job_id, salary
FROM oehr_employees
)
SELECT *
FROM pivot_data
PIVOT (
SUM(salary)
FOR department_id
IN ('||v('P5_DEPT_LIST')||')
)';
end;
Check https://apex.oracle.com/pls/apex/f?p=81782:5:0::::: to see the implementation.
Creating Matrix reports using Pivot XML query
Pivot XML query is another way of creating Matrix reports in APEX.
Unlike the Pivot queries, Pivot XML queries let us put a sub query in the in clause. The trouble with these queries is that we get an XMLType as an output. We then have to extract meaningful info from this XMLType.
Check https://apex.oracle.com/pls/apex/f?p=81782:5:0::::: to see the implementation that uses Pivot XML queries.
The query of a region that uses Pivot XML is shared below for your convenience.
WITH pivot_data AS (
SELECT department_id, job_id, salary
FROM oehr_employees
)
SELECT job_id,
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 10]/column[@name = "SAL"]') as "10",
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 20]/column[@name = "SAL"]') as "20",
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 30]/column[@name = "SAL"]') as "30",
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 40]/column[@name = "SAL"]') as "40",
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 50]/column[@name = "SAL"]') as "50",
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 60]/column[@name = "SAL"]') as "60",
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 70]/column[@name = "SAL"]') as "70",
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 80]/column[@name = "SAL"]') as "80",
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 90]/column[@name = "SAL"]') as "90",
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 100]/column[@name = "SAL"]') as "100",
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 110]/column[@name = "SAL"]') as "110"
FROM pivot_data
PIVOT XML
(
SUM(salary) as sal
FOR department_id
IN (select distinct department_id from pivot_data)
)
The query written above uses extractvalue function on top of the data returned by the Pivot XML operator. To understand this query, we have to understand the format in which we get the data from the Pivot XML operator. The last section on https://apex.oracle.com/pls/apex/f?p=81782:5:0::::: shows the data returned by Pivot XML operator and the query that generates this region. I have converted XMLType to CLOB in the query so that the data is visible on the APEX application. Have a look at that data and note the structure of the XML to better understand the following discussion.
Let me also share the screenshot of the XML returned by the Pivot XML operator for one of the job ids.

Following is the structure of this XML
PivotSet\item\column
Now, every item node has a pair of column nodes. These 2 column nodes have different values (DEPARTMENT_ID and SAL) for the name attribute. The column node with the DEPARTMENT_ID name tells us the column of the Matrix report to which the data belongs while the column node with the SAL name holds the data to be displayed.
Extractvalue function uses this info to create the report. Let me now share the code of the extractvalue function.
Extractvalue function uses this info to create the report. Let me now share the code of the extractvalue function.
extractvalue (department_id_xml,'/PivotSet/item[column/@name = "DEPARTMENT_ID" and column/text() = 10]/column[@name = "SAL"]') as "10"
department_id_xml, in the above code, is the name given by the Pivot XML operator to the XMLType column that it returns. Square brackets are used to filter nodes in XQuery. In the above code, item[column/@name = "DEPARTMENT_ID" and column/text() = 10] helps us find the item node which has a column node whose DEPARTMENT_ID has 10 as its value. Clearly, the SAL column node of this item node will hold the value of the Salary for department id 10. Check https://apex.oracle.com/pls/apex/f?p=81782:5:0::::: to make more sense of the discussion. column[@name = "SAL"]') then displays the value of the SAL column node of the same item node. Hence this code gives us the sum of salaries of employees for a job id and department id=10 combination.
The drawback of this approach is that you will have to create a column for all possible values that can possibly appear in the output.
The drawback of this approach is that you will have to create a column for all possible values that can possibly appear in the output.
Read http://docs.oracle.com/cd/E11882_01/appdev.112/e23094/xdb_xquery.htm to know more about XDB and XQuery.
Till next time!! :-)
11 comments:
Trying you code to get a pivot with a page item returns the following error:
failed to parse SQL query:
ORA-56901: non-constant expression is not allowed for pivot|unpivot values
Can you explain what version of Oracle 11g you are on?
Hi Tony,
The code and example is there on apex.oracle.com
https://apex.oracle.com/pls/apex/f?p=81782:5:0:::::
The version of the underlying db of apex.oracle.com is: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0
I had the same error as the Texan. I found that I had to alter the query that produced the column list in the page item, so each value was surrounded by single quotes, eg:
select ''''||listagg(department_id,''',''') WITHIN GROUP
(ORDER BY department_id) ||'''' from (select distinct department_id from oehr_employees);
Note that I then had to strip these back out in the PL/SQL for Column Attributes.
Oracle 11.2.0.3, Apex 4.2.2
Okay, adding a new question here.. If we wanted to add a sum to the mix:
begin
return 'with pivot_data as (
SELECT department_id,
job_id,
salary,
comm
FROM oehr_employees
)
SELECT *
FROM pivot_data
PIVOT (
SUM(salary),
SUM(comm)
FOR department_id
IN ('||v('P5_DEPT_LIST')||')
)';
end;
How exactly can we get the second set of columns for each department level total of commissions?
Thank you,
Tony Miller
LuvMuffin Software
Ruckersville, VA
Never Mind.. Had a dangling where in the select that was causing an issue, now able to get multiple sums in the pivot. Looking at the final issue of the page item to hold the in list item..
Thank you,
Tony Miller
LuvMuffin Software
Ruckersville, VA
Quick question, how do you make this work for an interactive report?
Sample code will remove all the pivot built columns at development time since the substitution variable is empty..
Hi Tony,
When did you move to Virgina?
It will help if you can create an example in apex.oracle.com. I haven't worked on APEX in the last few months. I was working on OBIEE but will definitely check it out if you can create an example.
Regards,
Vishal
Hi Vishal,
Is it possible to have a Dynamic matrix report with editable fields?
Kindly advise.
Thanks,
Check my post on reforms
Hi Vishal,
PIVOT in the Apex provides MAX of three PIVOT Columns or ROW columns or FUNCTIONS. we can not add more.
I have a requirement to add more than 3 PIVOT Columns, ROW columns, and FUNCTIONS. Could you please let me know if you know any custom approach.
Thanks in Advance.
awaiting your response.
Hi,
How can I add the double header, as in the first image, so that it appears: "Color {Yellow, Red, Blue}, Size {Small, Medium, Large}" as an example
Regards
Luis Sánchez
Post a Comment